基于方面的情感分析(Aspect Based Sentiment Analysis, ABSA)是一种细粒度的情感分析任务,旨在识别一条句子中一个指定方面(Aspect)的情感极性。
一个句子中可能含有多个不同的方面,每个方面的情感极性可能不同。
包含5个细粒度的子任务:
- Aspect Term Sentiment Classification (ATSC):一个Aspect term是句子中的一个词或词组。
- Aspect Term Extraction (ATE):抽取出一个句子中的Aspect term,可以建模为一个序列标注问题。
- Aspect Category Sentiment Classification (ACSC):一个Aspect category是预先定义的隐式描述句子中事物的类别。
- Aspect Category Detection (ACD):识别出一个句子中的Aspect category,可以建模为一个多标签分类问题。
- Opiniton Term Extraction (OTE)
参考链接:https://zhuanlan.zhihu.com/p/81513782
论文总结
| 序号 | 论文标题 | 发表信息 | 简单描述 | 代码 | 备注 |
|---|---|---|---|---|---|
| [0](#Deep Learning for Sentiment Analysis: A Survey) | Deep Learning for Sentiment Analysis: A Survey | 2018 | 情感分析综述 | [paper] | |
| 16.1 | Effective LSTMs for Target-Dependent Sentiment Classification | Coling 2016 | TD-LSTM/ TC-LSTM | [paper] | |
| [16.2](#Attention-based LSTM for Aspect-level Sentiment Classification) | Attention-based LSTM for Aspect-level Sentiment Classification | EMNLP 2016 | AT-LSTM/ ATAE-LSTM | [paper] | |
| 16.3 | A Hierarchical Model of Reviews for Aspect-based Sentiment Analysis | EMNLP 2016 | H-LSTM | [paper] | |
| 17.1 | Recurrent Attention Network on Memory for Aspect Sentiment Analysis | EMNLP 2017 | RAM | ||
| [19.1](#A Challenge Dataset and Effective Models for Aspect-Based Sentiment Analysis) | A Challenge Dataset and Effective Models for Aspect-Based Sentiment Analysis | EMNLP 2019 short paper | CapsNet/ CapsNet-BERT | [paper] [pytorch] | 胶囊网络需要再学习下 |
论文简述
Deep Learning for Sentiment Analysis: A Survey
摘要
本文首先对深度学习进行了综述,然后对其在情感分析中的应用现状进行了综述。
介绍
情感分析或观点挖掘是对人们对产品、服务、组织、个人、问题、事件、话题及其属性的观点、情感、情绪、评价和态度的计算研究。
该领域的开始和快速发展与社交媒体的发展相一致,如评论、论坛、博客、微博、推特和社交网络,因为这是人类历史上第一次拥有如此海量的以数字形式记录的观点数据。
早在 2000 年,情感分析就成为 NLP 中最活跃的研究领域之一。它在数据挖掘、Web 挖掘、文本挖掘和信息检索方面得到了广泛的研究。
这种发展原因在于观点是几乎所有人类活动的核心,是人类行为的重要影响因素。我们在做决策的时候,通常会寻求别人的意见。
然而,由于各种网站的出现,在网上查找和监测意见网站并提取其中的信息仍然是一项艰巨的任务。
现有的研究已经为情绪分析的各种任务产生了大量的技术,包括有监督和无监督的方法。近年来,将深度学习应用于情绪分析也变得非常流行。
深度学习
神经网络,深度学习
Word Embedding: Word2Vec (CBOW-小数据集,Skip-Gram-大数据集)、GloVe
AutoEncoder / Denoising AutoEncoder
自编码器神经网络是一个三层神经网络,其目标是使输出值近似等价于输入值。目标是学习输入的特征。
降噪自编码器(DAE)是自编码器的扩展,其中输入被破坏。思想是强制隐藏层发现更鲁棒的特征,并阻止自编码器简单地学习恒等变换。也就是说,模型应该在存在噪声时仍能重构输入。这种技术也体现在情感分析中,例如从文档中删除或添加一些文字不应该改变文档的语义。
Convolutional Neural Network
卷积神经网络(CNN)是一种特殊的前向神经网络,最初应用于计算机视觉领域。它的设计灵感来自人类视觉皮层。视觉皮层包含许多细胞,这些细胞负责在视野的小而重叠的亚区域(称为感受野)中检测光线。
卷积层可以提取局部特征,而不关心他们的位置如何。
Recurrent Neural Network
循环神经网络(RNN)在处理序列信息方面很受欢迎。理论上,RNN可以利用任意长序列的信息,但在实际应用中,由于梯度消失和梯度爆炸,标准RNN只能回顾几个时间步。
由于标准RNN不足,开发了 双向RNN、Deep Bidirectional RNN、Long Short Term Memory (LSTM)
LSTM:4个层交互,2个状态 hidden state and cell state,3个门 forget/input/output。通常用于顺序数据或树形结构的数据,处理数据的远程依赖关系。树形结构的LSTM- Tree-LSTM / 简化 - GRU。
Attention Mechanism
注意机制受到人类视觉注意机制的启发,人类的视觉注意力能够以“高分辨率”聚焦在图像的某个区域,同时以“低分辨率”感知周围的图像,然后随着时间的推移调整焦点。
Memory Network
针对QA问题引入了记忆网络 (MemNN)。End-to-End Memory Network (MemN2N)
Recursive Neural Network
递归神经网络(RecNN)是一种通常用于从数据中学习有向无环图结构(例如,树结构)的神经网络。给定句子的结构表示(例如,解析树),RecNN通过组合记号来产生短语的表示,最终生成整个句子,从而以自下而上的方式递归地生成父表示。
情感分析任务
主要在三个粒度级别研究情感分析:document level、sentence level、aspect level。
document level:将观点鲜明的文本(如产品评论)分类为整体pos/neg的观点。a single entity。
sentence level:对文档内单独的语句进行分类。然而,单独的语句不能假定为观点鲜明的。subjectivity classification 判断主观/客观。若主观,判断pos/neg。三分类问题:pos/neg/中立。
aspect level:提取和总结人们对实体表达的意见和实体的方面/特征。由aspect extraction, entity extraction, 和 *aspect sentiment classification *几个子任务组成。
举例:“iPhone的音质很棒,但是它的电池很烂”,实体提取应该把“iPhone”识别为实体,方面提取应该识别“音质”和“电池”是两个方面,方面情感分类应将对iPhone音质的情感分为正面,对iPhone电池的情感分为负面。
除此之外,情感分析还做emotion analysis, sarcasm detection, multilingual sentiment analysis这些方向。
Document Level Sentiment Classification
determine whether the document (e.g., a full online review) conveys an overall positive or negative opinion.
文本表示:BoW(忽略词序,几乎无法编码单词语义) - Bag-of-N-Grams(数据稀疏/高维)- word embedding。除此,也可以直接用 BoW 学习密集文档向量。
情感分类:传统监督学习/神经网络。利用数据特征(如产品评论)。
工作 方法 Moraes et al.34 使用Bow向量,发现在文档级别上ANN优于SVM 35 Bow缺点太多,提出Paragraph Vector,通过预测上下文单词来学习的。 36 研究情感分类的领域适应问题。Bow学习密集向量。基于Stacked Denoising Autoencoder。同时使用有/无标注数据。 37 引入半监督的autoencoder。修改损失函数达到特定于任务的表示。 38 BoW-CNN。Seq-CNN,通过连接多个单词的one-hot向量来保持单词的顺序信息。 39 提出考虑句子关系的NN来学习文档表示。CNN/LSTM学习句子表示,GRU编码句子语义及内在关系。 40 在review分类中同时考虑user和product信息,捕获全局线索。 41 42 考虑user和product信息,使用词和句级别的注意力机制。 43 提出 cached LSTM 模型。模型记忆被划分为不同遗忘率的几组。low rate:全局语义特征。high rate:局部特征。 44 2层注意力机制。词/句子。 45 视为一个机器理解问题。多层交互注意力机制。文档和伪aspect问题交互,学习aspect-aware的文档表示。 46 cross-lingual 情感分类。将情感信息从资源丰富的语言适配到资源贫乏的语言。使用2个层次结构化的attention-based LSTM。 47 迁移学习,cross-domain情感分类,使用对抗记忆网络。2个任务:情感分类、领域二分类。
Sentence level sentiment classification
determine the sentiment expressed in a single given sentence.
subjectivity classification:主观/客观
polarity classification:积极/消极
在现有深度学习模型中,一般视为三分类任务:positive、neural、negative。
同文档,句子表示也很重要。句子通常较短,可使用句法和语义信息(如parse trees, opinion lexicons, and pos tags)。其他信息,如评论评分、社会关系和跨域信息。
早期使用解析树,现在用CNN/RNN加上embedding。
工作 方法 49 50 51 使用各种RecursiveNN去得到embedding。 52 53 提出Dynamic CNN,使用dynamic K-Max pooling。CNN-rand/static/non-static/-multichannel。 54 Character to Sentence CNN,没有embedding,直接把字符one-hot,CNN训练。 55 56 57 LSTM。BiLSTM。CNN-LSTM。 58 joint CNN & RNN,短文本。利用CNN生成的粗粒度局部特征和RNN学习的长距离相关性。 59 LSTM & CNN。word2vec 和 linguistic embeddings。 60 将句法知识(如pos)编码在一个树状结构的LSTM中增强表示。 61 模型融合。金融微博和新闻的细粒度情感分类。 62 弱监督CNN。2步:用总体review rating学习句子表示,labels微调 63 上下文敏感词汇,加权和模型,BiLSTM,学习情感强度。 64 学习generalized sentence embeddings for cross-domain。分别设计CNN,从已/未标记的数据中联合学习两个隐藏的特征表示。 65 recurrent random walk network。opinionated tweets。利用用户的推文和社交关系。 66 CNN。从人类阅读的眼动数据中自动提取认知特征。。。 67 linguistically regularized LSTM。整合 情感词典/否定词/强度词。
Aspect level sentiment classification
aspect level sentiment classification considers both the sentiment and the target information, as a sentiment always has a target.
具有挑战,很难对目标与其周围上下文词的语义关联性进行建模。
三个重要任务:
- 目标上下文的表示:用之前的方法。
- 与其上下文正确交互的目标表示:学习目标嵌入,类似词嵌入。
- 识别指定目标的重要情感上下文(词):常用注意力机制,没有主流方法。
工作 方法 68 Adaptive RecursiveNN。 69 Aspect extraction and categorization
要进行aspect level的情感分类,需要有方面(或目标),可以手动给定或自动提取。
举例:“图像非常清晰”,“图像”是一个aspect term(or sentiment target)。方面分类:将相同的方面表达式分组到一个类别中。方面术语“图像”、“照片”和“图片”可以分组为一个方面类别,称为图像。
其他情感分析相关任务
- Opinion expression extraction:意见表达提取,旨在识别句子或文档中的情感表达。
- Sentiment composition:
- Opinion holder extraction:是识别谁持有意见的任务。
- Temporal opinion mining:时态意见挖掘,预测未来观点。随着时间推移,观点会发生改变。
- sentiment analysis with word embedding:嵌入词的情感分析。词嵌入在情感分析模型中起着重要作用。
- Sarcasm analysis:讽刺分析。
- Emotion analysis:情绪分析。主要的情绪包括爱、喜悦、惊讶、愤怒、悲伤和恐惧。情绪的概念与情感密切相关。
- Multimodal data for sentiment analysis:多模态数据的情感分析。如承载文本、视觉和听觉信息的数据,已经被用来帮助情感分析,提供额外的情感信号。
- resource-poor languages and multilingual sentiment analysis:资源贫乏语言与多语言情感分析。
- 其他:Sentiment Intersubjectivity、Lexicon Expansion、Financial Volatility Prediction、Opinion Recommendation、Stance Detection
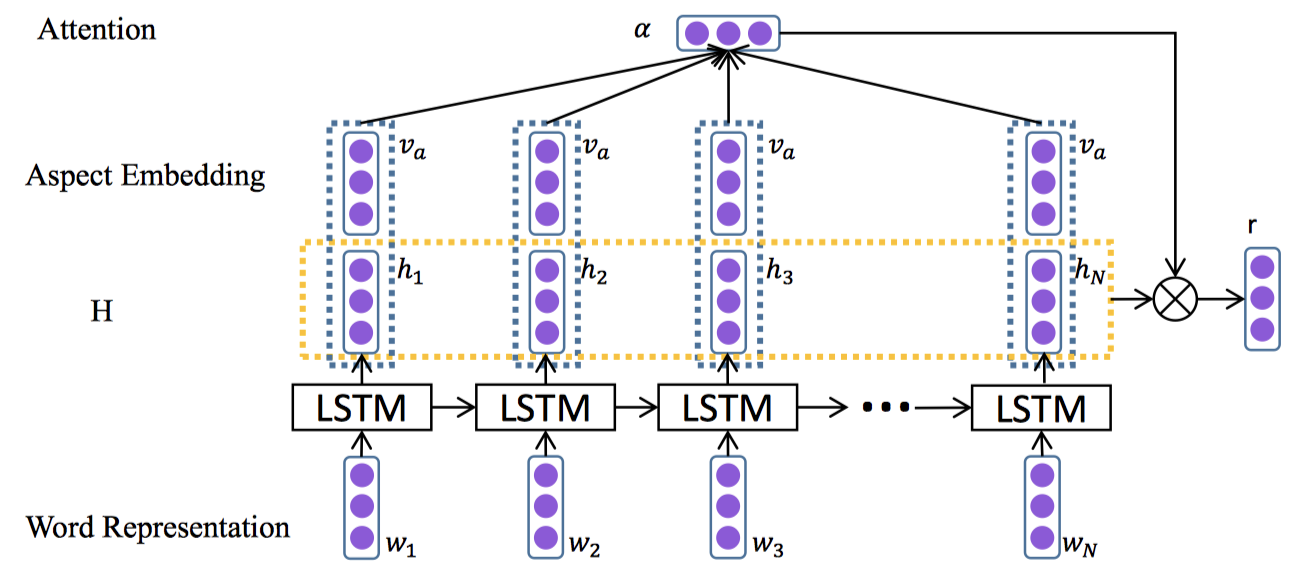
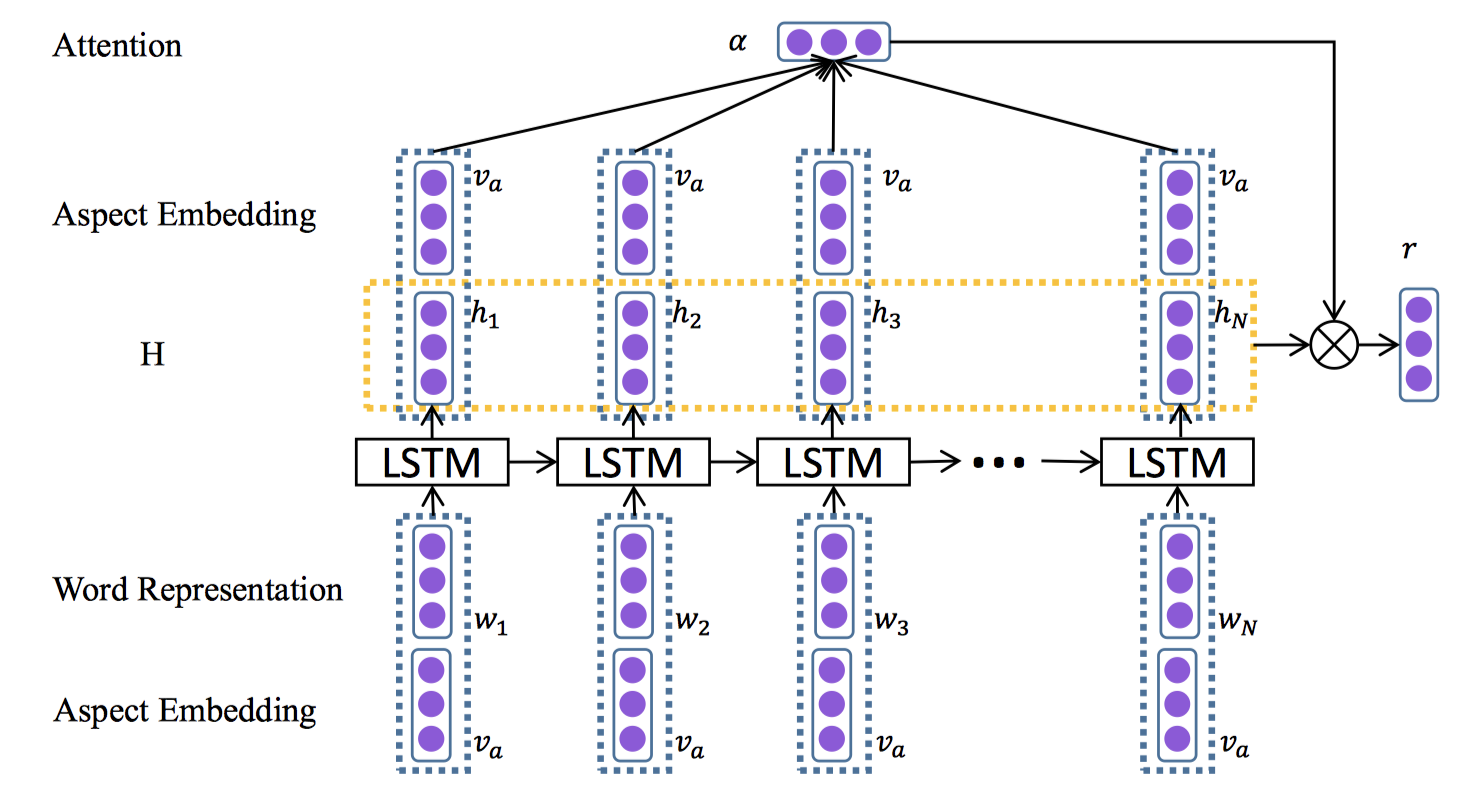
Attention-based LSTM for Aspect-level Sentiment Classification
介绍:
Aspect-level情感分类是情感分析中的一项细粒度任务。
本文揭示了句子的情感极性不仅由内容决定,而且与所关注的方面密切相关。
提出AT-LSTM模型,以不同方面作为输入时,注意机制可以集中在句子的不同部分。在2014SemEval数据集上进行了实验,达到最先进水平。
提出2种方法:
LSTM with Aspect Embedding (AE-LSTM):在将aspect向量连接到句子隐藏表示中以计算注意力权重
Attention-based LSTM with Aspect Embedding (ATAE-LSTM):将aspect向量附加到输入词向量中。
模型:
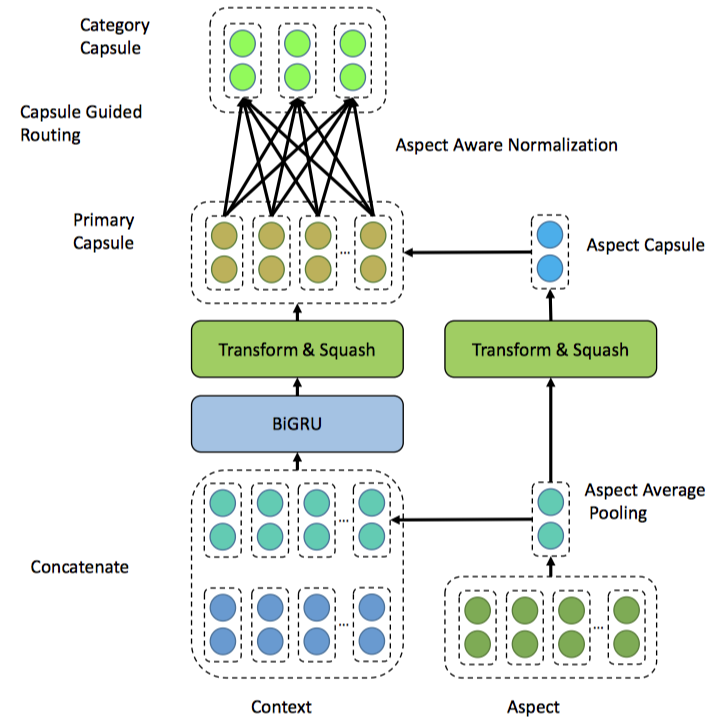
A Challenge Dataset and Effective Models for Aspect-Based Sentiment Analysis
介绍:
现有ABSA数据集中,大多数句子只包含一个或多个具有相同情感极性的aspect,这使得ABSA任务退化为句子级的情感分析。
经验型得知:1.句子级情感分类即使不考虑各个方面,仍可以用许多最新的ABSA方法获得不错的结果;2.在这些数据集上训练的高级ABSA方法,仍很难区分一句中多个方面的不同情感极性。
提出了一个新的大规模 MultiAspect Multi-Sentiment (MAMS)数据集,每个句子至少包含两个不同的方面,它们具有不同的情感极性。
提出了CapsNet和CapsNet-BERT模型,这些模型结合了NLP最新进展的优点。
在新数据集上的实验表明,所提出的模型显著优于最新的基线方法。
MAMS 数据集:
来自 Citysearch New York dataset,将每个文档划分为句子,去掉单词数超过70的句子。
创建2个版本数据集:
- ATSA:方面术语情感分析数据集。经验者进行标注。删除只包含一个或情感极性相同的多个方面的句子。提供术语起始位置。13854个实例。
- ACSA:方面类别情感分析数据集。预定义8个类别。只保留至少包含2个不同情感极性的类别的句子。8879个实例。
MAMS small:小版本MAMS数据集,便于与SemEval-14餐厅数据集比较。
模型:


- Post link: http://yoursite.com/nlp/sentiment_analysis/
- Copyright Notice: All articles in this blog are licensed under unless stating additionally.
若您想及时得到回复提醒,建议跳转 GitHub Issues 评论。
若没有本文 Issue,您可以使用 Comment 模版新建。
GitHub Issues