文本分类是自然语言处理中的一项基础任务,目的是将文本分配给指定标签中的一个或多个。
通过将近年来看过的顶会论文集中到一起,希望对以后的工作有一定的帮助。
参考链接:https://paperswithcode.com/task/text-classification
论文总结
| 序号 | 论文标题 | 发表机构 | 简单描述 | 论文及代码 | 备注 |
|---|---|---|---|---|---|
| 0 | Text Classification Algorithms: A Survey | 2019.4 | 文本分类综述。more | GitHub | weblink |
| 14.1 | Convolutional Neural Networks for Sentence Classification | ACL 2014 | TextCNN。more | ||
| 14.2 | A Convolutional Neural Network for Modeling Sentences | ACL 2014 | DCNN | ||
| 15.1 | Recurrent convolutional neural networks for text classification | AAAI 2015 | RCNN | ||
| 15.2 | A Sensitivity Analysis of Convolutional Neural Networks for Sentence Classification | 2015 | 对TextCNN的参数进行对比实验,得出设置经验。 | 论文 | |
| 16.1 | Hierarchical Attention Networks for Document Classification | NAACL 2016 | HAN | ||
| 16.2 | Recurrent Neural Network for Text Classification with Multi-Task Learning | IJCAI 2016 | TextRNN | ||
| 17.1 | Deep Pyramid Convolutional Neural Networks for Text Categorization | ACL 2017 | DPCNN | ||
| 17.2 | Very deep convolutional networks for text classification | EACL 2017 | VDCNN | ||
| 17.3 | Bag of Tricks for Efficient Text Classification | EACL 2017 | FastText | ||
| 17.4 | A Structured Self-Attentive Sentence Embedding | ICLR 2017 | Self-Attention | Attention.4 | |
| 18.1 | Joint embedding of words and labels for text classification | ACL 2018 | LEAM | tensorflow | |
| 18.2 | Baseline Needs More Love-On Simple Word-Embedding-Based Models and Associated Pooling Mechanisms | ACL 2018 | SWEM | tensorflow | |
| 18.3 | Sequence Generation Model for Multi-Label Classification | COLING 2018 | SGM | pytorch | |
| 18.4 | Investigating Capsule Networks with Dynamic Routing for Text Classification | EMNLP 2018 | Capsule。more | 理解胶囊网络 | |
| 18.5 | Universal Language Model Fine-tuning for Text Classification | ACL 2018 | ULMFiT。通用语言模型微调,迁移学习方法。包含很多训练技巧。 | 论文 官网 |
|
| 18.6 | Multi-Task Label Embedding for Text Classification | EMNLP 2018 | 1.利用标签描述信息 2.多任务学习,新任务来时可scale和transfer 3.增加新的有标注/无标注的数据任务时,hot/cold/zero update | ||
| 19.1 | Graph Convolutional Networks for Text Classification | AAAI 2019 | GCN。将文本和单词分别作为节点,文本与单词(TF-IDF)、单词间(PMI)的联系作为边。 | ||
| 19.2 | Adaptive Convolution for Text Classification | NAACL 2019 | 自适应卷积,根据不同输入(上一个卷积块的输出)动态生成filter。提出hash genetation。 | pytorch | |
| 19.3 | EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks | EMNLP 2019 | 文本分类的数据增强技术。同义词替换、随机插入、交换、删除。more | 论文 keras |
|
| 19.4 | Sequential Learning of Convolutional Features for Effective Text Classification | EMNLP 2019 | SCARN。联合CNN、RNN、Attention的优点。more | 论文 | |
| 19.5 | Enhancing Local Feature Extraction with Global Representation for Neural Text Classification | EMNLP 2019 | 利用全局表示增加局部特征抽取。more | ||
| Topic Memory Networks for Short Text Classification | EMNLP 2018 | ||||
| Neural Attentive Bag-of-Entities Model for Text Classification | CoNLL 2019 | 利用实体信息 | |||
| Simplifying Graph Convolutional Networks | ICML 2019 | GCN | |||
| Sentiment Classification using Document Embeddings trained with Cosine Similarity | ACL 2019 | ||||
| Improved neural network-based multi-label classification with better initialization leveraging label co-occurrence | NAACL 2016 | ||||
| Compositional coding capsule network with k-means routing for text classification | |||||
| Large-scale Multi-label Text Classification | |||||
| SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS | |||||
论文简述
Text Classification Algorithms: A Survey
大多数文本分类系统可以分解为以下四个阶段:特征提取、降维、分类器选择和模型评估。
文本分类分为4个级别:文档级别、段落级别、句子级别、子句级别(算法获得句子内的子表达式的相关类别)
Text Preprocessing 数据预处理:消除噪音
分词、去除停用词、俚语和缩略词、关键标点符号和特殊字符、拼写检查、Stemming 词干提取等Feature Extraction 特征抽取:信息特征化
- Weighted word 加权词:
- TF/Bag of Words (BoW):最常用的,词袋,文本的主体被认为是一袋单词,单词列表按照个数被创建。忽略了语法和顺序,但是利用了计数特征。容易导致一些特别常用的词在文本表示中占主要地位。使用one-hot编码,由于词汇量可能达到数百万,导致矩阵十分稀疏。
- Term Frequency-Inverse Document Frequency (TF-IDF):tf 改进了召回率,idf 提高了准确率。克服了文档中常见术语的限制,但是无法考虑词之间的相似性。
- Word embedding 词嵌入:
- Word2Vec:CBOW-预测给定上下文的单词、Skip-gram model-预测给定单词的上下文,保持句子的句法和语义信息。缺点是没有充分利用语料信息。
- Global Vectors (GloVe):与word2vec相似。但是基于全局词频统计的词表征工具,它把单词表示成一个由实数组成的向量,捕捉到单词间的语义信息,如相似性、类比性,通过对向量的计算,如欧几里得距离和余弦相似度,可以计算两个单词的相似性。
- FastText:类似于CBOW,两种模型都是基于Hierarchical Softmax,但引入了N-gram信息。适合大型数据+高效的训练速度,支持多语言表达,专注于文本分类。
- Context2vec:从双向语言模型学习词向量。ELMo,相对于GPT和Bert,lstm特征抽取能力弱于transformer,双向拼接融合比一体化融合弱。
- Weighted word 加权词:
Dimensionality Reduction 降维:
Classification Techniques 分类器:
传统方法 - Rocchio Classification:
集成算法:
Boosting、Bagging。投票分类技术。Boosting,弱学习算法
传统且流行的算法:
Logistic Regression (LR)、Naïve Bayes (NB)、K-Nearest Neighbor (KNN)、Support Vector Machine (SVM)
基于树的算法:
Decision Tree、Random Forest
Conditional Random Field (CRF):
Deep Learning:
RNN、CNN、DBN、HANSemi-Supervised Learning:
Evaluation 评价方法:
- confusion matrix 混淆矩阵、accuracy 准确率、precision 精确率、recall 召回率、F1-score
- macro-averaging、micro-averaging
- Matthews Correlation Coefficient (MCC)
- Receiver Operating Characteristics (ROC)
- Area Under ROC Curve (AUC)
Convolutional Neural Networks for Sentence Classification
摘要
将基于预训练词向量的卷积神经网络用于句子级别分类。
一个简单的CNN只需很少的超参数和静态向量就能在多个数据上取得优异的结果。
通过微调学习特定任务的向量可以进一步提升性能。
对架构提出了一个简单的修改,允许同事使用特定任务的和静态的向量。
介绍
文本分类的关键在于准确提炼文本的中心思想,CNN利用卷积操作提取局部特征,利用池化提取关键信息。
模型
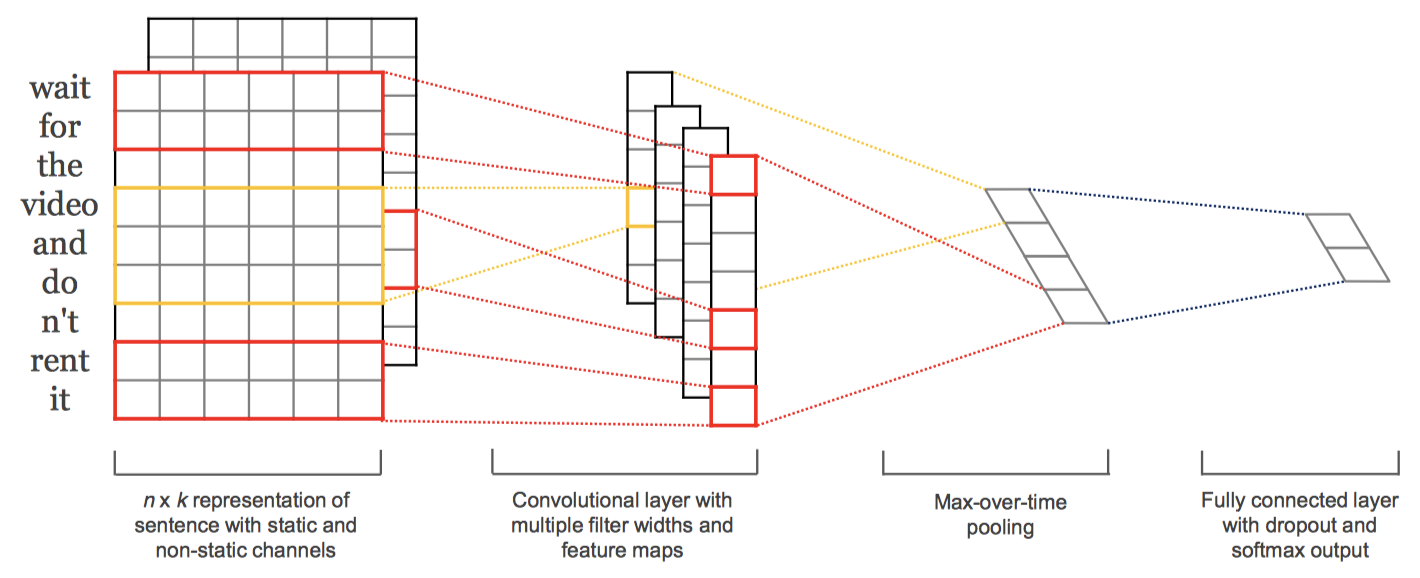
基础结构
长度为 $n$ 的句子可以表示为:$\mathbf{x}_{1:n}=\mathbf{x}_1\oplus\mathbf{x}_2\ \oplus,…\oplus,\mathbf{x}_n$
一个 $filter$ 为:$\bf{w} \in \mathbb {R}^{hk}$
对 $h$ 个词的窗口进行卷积:$c_i = f(\mathbf{w} \cdot \mathbf{x}_{i:i+h-1} + b)$
产生一个$feature\ map$:$\mathbf{c} = [c_1,c_2,…,c_{n-h+1}] \in \mathbb{R}^{n-h+1}$
最大池化之后:$\hat{c}=max {\mathbf{c}}$
有 $m$ 个$filter$:$\mathbf{z} = [\hat{c_1},\hat{c_2},…,\hat{c_m}]$
正则化
池化层后面加上全连接SoftMax层做分类任务。为了防止过拟合,一般会添加L2和Dropout正则化方法。Dropout:$y = \mathbf{w} \cdot(\mathbf{z}\ \circ\ \mathbf{r}) + b$
模型变体
CNN-rand:所有词向量被随机初始化。
CNN-static:使用word2vec预训练词向量,其他unknown词随机初始化,训练过程中保持不变。
CNN-non-static:使用预训练词向量,训练过程中微调。
CNN-multichannel:使用两个通道,一个为static,一个为non-static,微调时只有一个通道更新参数。都用word2vec初始化。
A Convolutional Neural Network for Modeling Sentences
- 摘要
Adaptive Convolution for Text Classification
- 摘要
- 介绍
Universal Language Model Fine-tuning for Text Classification
摘要
迁移学习在计算机视觉方面取得了很多成功,而在自然语言处理还没有太多进展,仅仅停留在使用 word2vec 或多任务学习的阶段,需要从头开始训练。本文提出了一个针对NLP的有效迁移学习方法,通用语言模型微调(ULMFiT),同时介绍了用于微调模型的相关技巧。而且在100个小标注样本上微调的性能和100倍数据从头开始训练的性能等价。
介绍
很多深度学习模型,要 从头开始训练,大量数据,收敛时间长,考虑迁移学习技术 - 微调的预训练词向量。
基于微调的迁移技术在NLP还不成功。
LM fine-tuning:小数据上过拟合,用分类器微调时会灾难性遗忘LM的知识。
根据深度学习模型 “越底层的特征越通用,越顶层的特征越特殊”这个特点,可以将其分为两部分,底部是一个通用的模型,由一个大型数据集预训练得到,其能够使小数据集避免从头开始训练(随机初始化参数通常比预训练参数微调要差),顶部则根据下游任务从头开始训练。
模型
General-domain LM pretraining:在Wikitext-103数据集(包含 28,595 篇维基百科文章和 1030 亿个单词)上训练语言模型,从而捕获不同层次文本的一般特征。
Target task LM fine-tuning:针对目标任务的小数据微调LM。使用了2个trick,学习不同层次文本针对特定任务的特征。
- Disciminative fine-tuning 区分微调:由于不同层捕获的信息不同,需要不同程度的微调。给每层设置不同的学习率(底层通用较小,顶层特殊较大),先通过微调最后一层参数确定一个合适的学习率,然后下一层使用上一层1/2.6的学习率。
- Slanted triangular learning rates 斜三角学习率:学习率先快增后慢减。为了适应特定任务特征的参数,让模型在开始先用较小学习率,快速增大收敛到合适的区域,再从大学习率开始慢慢减小进行优化。
Target task classifier fine-tuning:训练顶层分类器。用了4个trick。
- Concat pooling:如仅使用RNN最后时刻步的隐层状态,会丢失很多信息。所以将最后时刻步的隐层、隐层的最大池化、平均池化连接在一起。
- Gradual unfreezing:直接 fine-tune 整个网络会导致网络遗忘之前预训练得到的通用特征,但是fine-tune过于谨慎会导致收敛太慢。本文使用逐层解冻的方法,从最后一层(包括最特殊的知识)开始自顶向下,每一个epoch加入一个解冻层,即1epoch微调顶层,2epoch微调上两层,以此类推。文中提到的chain-thaw 每次训练单独一层,不用累加的方式。
- BPTT for Text Classification(BPT3C):使用基于时间的反向传播(BPTT)来训练语言模型,使得能够对大的输入序列进行梯度传播。文档划分为batch_size为b的批次;每个batch开始训练前,用上一个batch的最终状态初始化模型;跟踪平均值和最大池的隐藏状态;梯度反向传播到隐层状态有用的batch。
- Bidirectional language model:预训练前向LM和后向LM,每个LM独立使用BPT3C微调分类器,最后结果取平均。
学习:
文中提到的ULMFiT方法,可以尝试使用在nlp迁移学习中。
之后在调模型的时候,可以使用文本中提到的一些技巧。
EDA: Easy Data Augmentation Techniques
摘要
提出EDA,简单的数据增强技术来提升文本分类任务的性能。包括同义词替换、随机插入、随机交换、随机删除。在小数据集上结果较强;使用50%的训练集可达到所有数据的相同的精度。
方法
同义词替换:忽略停用词,随机选择n个词,从同义词表中随机选择一个替换。
随机插入:忽略停用词,随机选择一个词的同义词,插入任意位置。重复n次。
随机交换:随机选择句子中两个词,交换位置。重复n次。
随机删除:以概率p随机删除句子中的词。
用$\alpha$表示句子中被改变的词的比例。$n=\alpha l$。$n_{aug}$表示增加的句子数。
结论
Sequential Learning of Convolutional Features for Effective Text Classification
摘要
CNN的关键挑战:卷积滤波器和最大池化。提出SCARN模型,同时利用CNN和RNN的优点。
介绍
在图像处理方面,深度卷积神经网络的有效性有很好的解释,但对于文本它的成功并没有太多理解。
问题1:固定卷积窗口是否保留了文本的序列信息?
问题2:最大池化选择的特征是否总是输入的最重要特征?
理解卷积和池化
卷积操作
缺点:遗失了顺序信息。将输入句子随机打乱/交替打乱,并使用卷积窗口从1到最长句子长度进行实验。实验结果说明CNN不能完全整合顺序信息,且获取序列信息的能力随着窗口变大而减小。
优点:能够学习特定任务的词嵌入。卷积层本质上是一个嵌入变换,可以将词原有的语义知识嵌入转换为适合此任务的嵌入。卷积层能够鲁棒的创建一个处理任何特定任务噪声的变换。
池化操作
越多不代表越好。实验选择所有滤波器的第n个最高值,n增加时,数据集性能随机变化,说明n的大小与任务的重要性之间没有明显联系。
模型
两个子网络:卷积循环网络,使用k个filters对文本进行单窗口卷积;循环注意力网络。
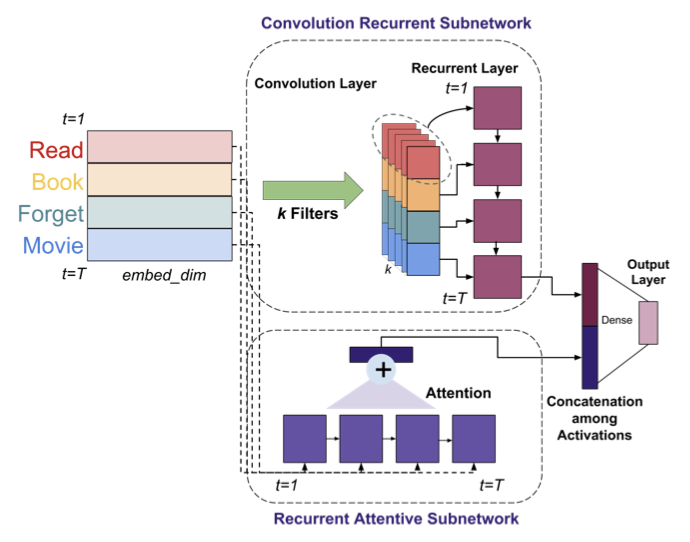
实验分析
SCARN模型比线性模型和基于词向量的模型好,因为它们不能合并顺序信息。
比LSTM/Bi-LSTM模型性能好,因为它们虽然可以学习顺序信息,但缺乏学习特定任务的特征表示的能力。
比CNN/DCNN好,因为缺乏RNN采用的学习顺序信息的方式。
比concat-SCARN模型好,就是将卷积输出和原始词向量进行连接,连接后的输出使用LSTM和Attention。因为卷积输出和原始词向量的分布不一致,但是如果加上batch normalization又回破坏潜在的语义信息。而SCARN模型的每个子网输出都使用relu激活,使之有相似的分布。
Enhancing Local Feature Extraction with Global Representation for Neural Text Classification
摘要
传统的局部特征驱动模型都通过深度叠加或者混合建模来学习长依赖的。
本文提出新的Encoder1-Encoder2结构,将全局信息融合到局部特征中。Encoder1作为全局信息提供者,Encoder2作为局部特征提取器直接送入分类器中。同时还会设计它们之间的交互。
此模型能够学习任务特定的局部特征,从而避免复杂的上层操作。
介绍
local feature driven models:利用显式局部提取器识别关键局部模式,然后分类。
局部特征抽取虽然有好的解释性和性能,但缺点仍存在。如果局部提取器从一开始不能捕获到重要信息,那么就需要复杂的上层结构来修正不精确的局部表现。
为了解决此问题,作者独创性的使用两个编码器,一个使用任意模型抓去全局信息,一个


- Post link: http://yoursite.com/nlp/text_classification/
- Copyright Notice: All articles in this blog are licensed under unless stating additionally.
若您想及时得到回复提醒,建议跳转 GitHub Issues 评论。
若没有本文 Issue,您可以使用 Comment 模版新建。
GitHub Issues